
I big data e il machine learning hanno riportato alla luce il teorema di un reverendo inglese del ‘700.
Thomas Bayes nacque nel 1701 nella contea inglese di Hertfordshire, frequentò l’università di Edimburgo dove studiò logica e teologia e fu successivamente ordinato ministro presbiteriano. Il suo ministero non gli impedì di coltivare la grande passione per la matematica che aveva manifestato fin da ragazzo. Non si sa molto in realtà della vita del reverendo Bayes se non che alla sua morte, avvenuta nel 1761, lasciò in eredità due paper che non era riuscito a pubblicare in vita: uno di questi, Essay Towards Solving A Problem In The Doctrine Of Chances, è considerato una degli articoli più famosi nel campo delle scienze sociali in quanto ha gettato le fondamenta delle moderne metodologie di inferenza statistica.
Il teorema di Bayes
Bayes si chiese come fosse possibile stimare le probabilità di un determinato fenomeno, avendo a disposizione solo poche osservazioni. Il metodo innovativo sviluppato dal reverendo prevedeva di partire da alcune ipotesi iniziali, analizzare le osservazioni e poi ragionare all’indietro (reasoning backward) per verificare l’attendibilità delle ipotesi iniziali ed eventualmente modificarle a seguito delle evidenze.
Un semplice esempio ci può aiutare a capire il funzionamento della cosiddetta inferenza Bayesiana. Supponiamo di partecipare ad una lotteria di cui non conosciamo le regole, cioè non sappiamo qual è la proporzione di biglietti vincenti sul totale. Formuliamo quindi 3 teorie, come ipotesi di partenza, che prevedono una percentuale di biglietti vincenti rispettivamente pari al 30%, 50% e 70% del totale. Attribuiamo una probabilità del 25% alle due ipotesi estreme (30% e 70%) e del 50% all’ipotesi centrale (50%). Compriamo 3 biglietti che risultano tutti vincenti dopo le prime 3 estrazioni: come possiamo modificare le ipotesi iniziali sulla base delle osservazioni?
I risultati sono riportati nella tabella 1.

Calcoliamo innanzitutto quale sarebbe stata la probabilità di avere 3 biglietti vincenti consecutivi con le 3 teorie che avevamo formulato, le cosiddette probabilità condizionate: se fosse vera la Teoria 1 (30% di biglietti vincenti) la probabilità sarebbe stata del 2,7% (0,3 X 0,3 X 0,3); con la Teoria 2 del 12,5% (0,5 X 0,5 X 0,5) e con la Teoria 3 del 34,3% (0,7 X 0,7 X 0,7).
Le estrazioni a cui abbiamo assistito ci suggeriscono quindi che la Teoria 3 è più probabile della 2 che è molto più probabile della 1. Tuttavia dobbiamo anche tener conto delle nostre ipotesi iniziali, in cui attribuivamo un peso doppio alla Teoria 2 rispetto alle altre. Moltiplichiamo quindi la probabilità degli eventi osservati (probabilità condizionate) con le nostre probabilità iniziali: se riproporzioniamo a 100 i valori che otteniamo, avremo le probabilità finali delle 3 teorie: poche osservazioni sono state sufficienti per farci quasi escludere la Teoria 1 (passata dal 25% al 4%) mentre la Teoria 3 è passata dal 25% di probabilità iniziale al 55%, diventando quindi l’ipotesi a cui attribuiamo maggiore peso.
Il teorema di Bayes stabilisce quindi che per calcolare le probabilità di un evento occorra partire da ipotesi iniziali definite prior probabilities che vengono trasformate in posterior probabilities sulla base delle osservazioni che abbiamo a disposizione. Una buona stima (posterior) dipende sia dalle ipotesi di partenza (prior), la nostra opinione iniziale, che dalla qualità e numerosità delle osservazioni che abbiamo a disposizione, che vengono utilizzate per raffinare e calibrare le ipotesi iniziali.
La teoria di Bayes ha rappresentato per molto tempo una nicchia della statistica: la metodologia basata sulle prior veniva considerata poco rigorosa, in quanto introduceva degli elementi di soggettività (le ipotesi iniziali, sono spesso basate su convinzioni personali) e inoltre il processo di continua revisione delle ipotesi basato sulle osservazioni era poco applicabile ai suoi tempi. L’era dei big data ha però riportato alla ribalta il teorema di Bayes: utilizzando l’inferenza Bayesiana è possibile calibrare in tempo reale le nostre ipotesi di partenza sulla base del flusso continuo di dati che abbiamo a disposizione. Ad esempio, molti degli algoritmi di machine learning utilizzano un approccio bayesiano: partono con delle impostazioni iniziali che poi aggiornano costantemente sulla base delle informazioni acquisite nel tempo, quella che è appunto l’essenza del learning.
“Il pensiero critico richiede che tutti pensiamo come Bayesiani, aggiornando la nostra conoscenza sulla base delle nuove informazioni.” (Daniel Levitin)
Bayes e la pandemia
Saper utilizzare il modello bayesiano ci consente di evitare errori di valutazione che in alcuni casi potrebbero risultare determinanti. Facciamo un esempio molto semplice.
Supponiamo di essere in presenza di una pandemia come il Covid-19. E’ stato sviluppato un test sierologico in grado di determinare se una persona abbia contratto il virus: il test ha un livello di efficacia del 90%, cioè ha un margine di errore del 10% (il tasso di falsi positivi è del 10%). A questo punto selezioniamo un volontario a caso, completamente asintomatico, gli somministriamo il test e otteniamo un risultato positivo: qual è la probabilità tra 0 e 100% che la persona abbia realmente contratto il virus?
La risposta più comune e immediata è…90%. Sbagliato! Il valore dipende dalla distribuzione del virus nella popolazione, che in questo caso rappresenta la nostra prior. Supponiamo di aver ragione di ritenere che in questo momento il Covid-19 sia diffuso nel 10% della popolazione. Questo significa che su un campione di 100 persone scelte a caso, 90 sono negativi e 10 sono positivi. La situazione è descritta nella tabella 2.
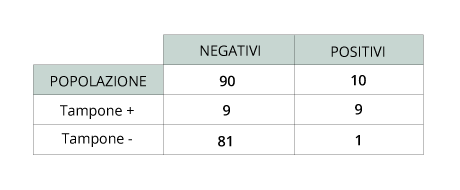
Se effettuo un tampone con efficacia al 90% sui 90 negativi, otterrò 9 falsi positivi. Sui 10 positivi, otterrò invece 1 falso negativo. Questo significa che su un totale di 100 tamponi, otterrò 18 risultati positivi (9+9) di cui 9, cioè il 50%, falsi positivi. Per cui se sono risultato positivo, ho addirittura il 50% di probabilità di non esserlo. Per questo la procedura standard prevede che i test rapidi, se positivi, siano immediatamente seguiti da un test più approfondito, con un livello di affidabilità superiore (negli sportivi che effettuano questi test frequentemente, abbiamo più volte assistito a un ribaltamento del risultato!). Non si pone il tema invece per i falsi negativi: con questa distribuzione di partenza infatti è solo 1 su un totale di 82 (1+81) cioè l’1,2%: per questo non viene effettuato un altro tampone di verifica se il risultato è negativo.
E’ ovvio che la situazione sarebbe molto differente se la distribuzione del Covid nella popolazione, cioè la nostra prior, fosse più elevata, ad esempio il 30%. In questo caso il rischio di essere un falso positivo si abbasserebbe al 21% e quello di essere un falso negativo salirebbe al 5%. Questo ci fa capire, quanto calibrare bene le assunzioni sulla distribuzione delle probabilità iniziali può impattare in maniera significativa sulla validità dei risultati che stiamo analizzando.
La previsione in presenza di poche osservazioni
Quello che abbiamo evidenziato nell’esempio del Covid, può essere generalizzato a tutti i casi in cui dobbiamo effettuare delle stime in presenza di poche osservazioni. In questo caso, i due studiosi Brian Christian e Tom Griffiths, nel loro libro Algorithms to Live By, sostengono come sia fondamentale capire se la distribuzione di partenza è una campana o una legge di potenza: a seconda dei due casi, il teorema di Bayes offre infatti due soluzioni molto differenti.
La vita media, l’altezza, il peso, la temperatura, le dimensioni dei frutti sono tutti esempi di grandezze con distribuzione a campana, cioè con una media attorno alla quale si raggruppano gran parte delle osservazioni e una scala di valori ben definita.
Al contrario la dimensione delle città, la capitalizzazione delle società in borsa, i click sui siti web, gli incassi al botteghino dei film, la ricchezza e il reddito sono tutti fenomeni caratterizzati da leggi di potenza: gran parte delle osservazioni hanno numeri molto piccoli mentre un ristretto numero di casi sono caratterizzati da valori molto grandi (molti nani, pochi giganti). Non c’è una scala di riferimento: sono fenomeni caratterizzati da forte disuguaglianza dove il grande diventa sempre più grande.
Se il fenomeno che stiamo osservando ha una distribuzione a campana, il teorema di Bayes suggerisce di adottare la regola della media (Average Rule): utilizzare la media della distribuzione come punto di riferimento per le nostre previsioni. Se abbiamo di fronte un bambino di 6 anni possiamo prevedere ragionevolmente che possa vivere fino a 77 anni (poco più della media di 76 anni…perché fino a 6 è già arrivato) mentre se incontriamo un anziano di 80 anni potremmo azzardare qualche anno in più, magari fino a 85. Nelle distribuzioni normali la media rappresenta un magnete e poche osservazioni si discostano significativamente.
Al contrario, per fenomeni caratterizzati da leggi di potenza, il teorema di Bayes suggerisce di utilizzare la regola della moltiplicazione (Multiplicative Rule): moltiplicare la quantità osservata fino a quel momento per una costante, che può ad esempio avere un valore tra 1 e 2. Ad esempio se osserviamo un film che ha incassato fino ad oggi $10 milioni, possiamo ipotizzare che gli incassi totali saranno $14 milioni (moltiplichiamo per 1,4).
La logica di fondo che è che le leggi di potenza non hanno una scala ben definita e il concetto di media non ha senso: per cui ci possiamo aspettare che il grande continui a crescere in proporzione a quanto è cresciuto finora mentre il piccolo continui a rimanere piccolo.
Con questa logica se osserviamo due start up A e B partite l’anno scorso nello stesso settore di cui la prima ha già raggiunto 2 milioni di fatturato e l’altra solo €500.000, possiamo ragionevolmente aspettarci che il prossimo anno A possa toccare 3 milioni mentre B possa crescere fino a €750.000 (moltiplichiamo per 1,5). La nostra aspettativa più ragionevole è quindi che il gap tra le due aziende continui ad aumentare e non che l’azienda B recuperi il terreno perduto.
In presenza di poche osservazioni, la scelta della prior indirizza quasi completamente la nostra previsione. Le prior che utilizziamo sono spesso influenzate dalle nostra esperienza personale. Supponete di essere in fila dal medico per una visita: in condizioni normali il vostro tempo di attesa è di circa 20 minuti. Oggi però state aspettando già da 40 minuti. Cosa fate? Se pazientate ancora perchè pensate che avendo già aspettato più del solito la situazione dovrebbe sbloccarsi da un momento all’altro vuol dire che avete una prior per i tempi di attesa distribuita come una normale e quindi state utilizzando la regola della media. Se ve ne andate perché pensate che dev’essere successo qualcosa e quindi i tempi potrebbero prolungarsi ancora a lungo state utilizzando una prior “legge di potenza” secondo la quale la migliore previsione di quello che dovrete aspettare è quello che avete aspettato fino ad ora (regola della moltiplicazione).
I rischi del rumore
Ci sono situazioni in cui le nostre ipotesi di partenza sono corrette ma sono le osservazioni che utilizziamo successivamente a portarci fuori strada: in sostanza quando passiamo dalla prior alla posterior peggioriamo la nostra stima di partenza.
Questo rischio è diventato particolarmente importante con i moderni mezzi di diffusione delle informazioni e con i social media. Gran parte delle informazioni che utilizziamo per validare le nostre ipotesi di partenza sono di bassa qualità perché derivano sempre meno dalla nostra esperienza diretta ed in misura sempre maggiore da quanto riportato da altre persone. Innanzitutto la rappresentazione degli eventi da parte dei media non rispecchia la loro frequenza nel mondo reale; inoltre gran parte delle notizie sono soltanto rumore. Il rischio che corriamo è che più informazioni utilizziamo, più peggioriamo le nostre ipotesi di partenza: diviene quindi fondamentale capire quali dati utilizzare e quali scartare.
Per utilizzare al meglio i nostri modelli mentali dobbiamo proteggerci dal rumore e focalizzarci solo su quello che serve per decidere. Questa è anche la missione di ThinkinPark.
“Se vuoi fare buone previsioni, cerca di proteggere le tue prior. Può sembrare controintuitivo, ma questo potrebbe significare ignorare le notizie.” (B.Christian & T.Griffiths)

Bibliografia:
Bernstein, Peter L. Against the Gods: The Remarkable Story of Risk. John Wiley & Sons, 1998.
Christian, Brian; Griffiths, Tom. Algorithms to Live By: The Computer Science of Human Decision. William Collins, 2016.
Ellenberg, Jordan. How Not to Be Wrong: The Power of Mathematical Thinking. Penguin Books, 2014.
Mauboussin, Michael J. The Success Equation: Untangling Skill and Luck in Business, Sports and Investing. Harvard Business Review Press, 2012.